Content-addressable storage with postgres
At work we’ve got a database backed email system that’s running into some performance issues. In particular, we’re placing the database’s disk under a lot of write load.
I’ve had an idea that we could use content-addressable data to reduce the amount we write to disk, and get better performance from a smaller database.
This post is an exploration of some techniques that we might look at using to do this in postgres - they’re new to me, and as yet untested in a production environment.
Our email system
We manage a pretty high traffic website at work. One of the more interesting features we have is a system where users can subscribe to certain pages, and receive email updates whenever a page is updated.
Emails are customised for each change and each subscriber, so roughly speaking
if we have m content changes and n subscribers, we’ll send out m×n unique
emails.
Since a single update to a page will often need to send a lot of emails we can’t just do this synchronously, so we use a queue (or several, actually).
Simplifying things a bit:
- a single message is placed on a queue for each content change
- a worker process picks these up, finds all the subscribers for the change, and places each combination of change and subscriber as a message on a second queue
- a second worker picks each of these messages up and generates a customised email that’s specific to this change and this subscriber. This email is written to the database, and then eventually yet another message is placed on yet another queue - this time saying “delivery the email in the database with this ID”
- finally, a third worker picks each of the delivery messages from the queue, finds the email in the database corresponding to the ID in the message, and sends it to our email provider
As a sequence diagram, this looks like:
Our email system and its problems
I’m sure the above all looks very impressive, but I’ve already mentioned that this system is starting to have problems. Why?
Some pages on our website have a lot of subscribers, and sometimes lots of pages with lots of subscribers get lots of changes. Obviously, this means we have to send lots of emails.
When this happens, things tend to get very slow, and we end up with a huge queue of emails to send.
At the same time, our database metrics start to look a little bit scary:
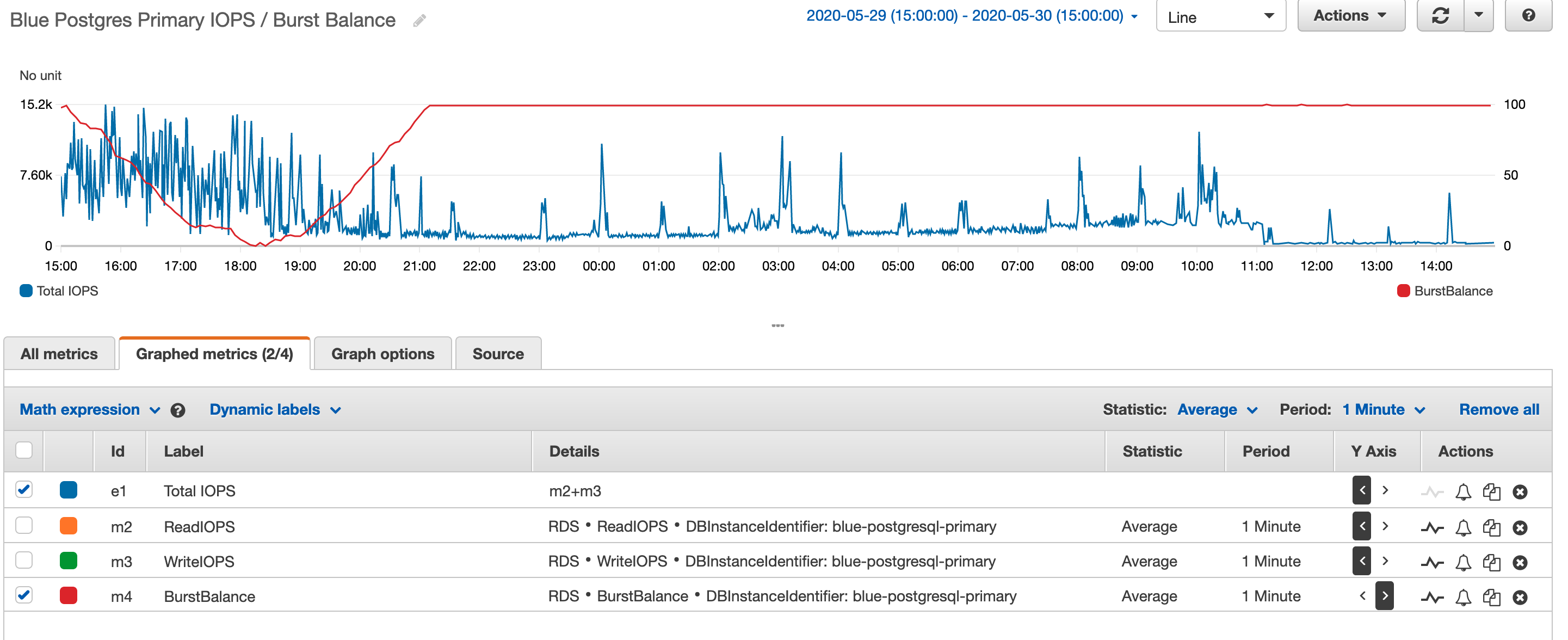
At the time this screenshot was taken, our database had enough allocated storage to be allowed 4,500 IOPS (input / output operations per second). Having a sustained period of more than 7,000 IOPS caused the disk to eat through its burst balance, resulting in severely degraded performance.
As a short term fix, we made the disk bigger to increase the IOPS thresholds we get. This should mean we can process many more emails before we start running into issues. However - bigger disks cost more money, and as demand for emails grows, this approach isn’t going to work forever.
Perhaps there are some changes we could make that would reduce the load on the database, and allow the system to perform well without needing enormous disks.
Where’s the performance bottleneck?
I haven’t had time to do a deeper analysis of our database metrics yet, but there’s a particular part of this system that stands out to me as something that’s going to put a lot of write load on the database.
… a second worker picks each of these messages up and generates a customised email that’s specific to this change and this subscriber. This email is written to the database…
This email is written to the database…
We’re writing every single email we want to send to the database - like the whole thing - subject, body, the lot.
Since we send millions of emails every day, this is a pretty hefty amount of data.
A lot of these emails are quite similar though - we might send out a particular content change notification to 100,000 subscribers, but 90% of the emails is the same for every subscriber - the only differences will be little things like “Hello $name,” and “use this link (https://example.com/Ov4rZrfNjV) to unsubscribe”.
We could reduce the amount of duplicate data we need write to the database by storing the bits that don’t change in the email once (as a template), and only storing the values for the placeholders for each subscriber.
At query time, we’d need to find the right template, and populate it with the placeholder values to get the email we actually want to send.
There are probably a few ways we could achieve this, but I’m interested in exploring how we might store the templates as content addressable entries in postgres, so I’m going to explore that.
What is content addressable data, and why should we consider it?
“Content addressable” data is data that can be addressed based on its content, instead of its location. This usually means the data is hashed, and the hash is used as a key to look up the data.
This feels like it might be useful in our case because we will have many
“process change + subscriber” jobs running concurrently, attempting to generate
the same email template. They can all hash the email template they generate,
and then use an insert ... on conflict do nothing; to store the template in a
table keyed on its hash. This guarantees that each template will only be
written once, and concurrent jobs can use the hash to refer to the template,
even if they weren’t the lucky job that got there first and wrote it to the
database.
(Now that I’ve got this far into writing this post, I think a more elegant way of solving this would be to have the worker that only runs once for each content change create the email template. There would be no need to mess around with hashing to achieve that. But I’ve started this line of thought now, so let’s finish it.)
What would this look like in postgres?
At the moment we’ve got an email table with a body column, something like this:
create table emails
(
body text,
email_address text,
);
As discussed, this isn’t ideal because we have to store almost the exact same email over and over again, once for each email address we’re going to send it to.
Instead, we’d want this table to contain a reference to a template and some placeholders to fill in. Something like this:
create table body_templates
(
id bytea not null constraint body_templates_pk primary key,
template text
);
create table emails
(
body_template_id bytea constraint emails_body_templates_id_fk references body_templates,
placeholders text[],
email_address text
);
When we need to generate a new email, the worker can do something like:
insert into body_templates (id, template)
values ($1, $2)
on conflict do nothing;
where $1 is the hash (say sha256) of the template, and $2 is the template
(which might be something like “Hello %s, thanks for subscribing. To
unsubscribe, click here: %s”).
(It would be possible for the worker to get the DB to do the hashing using
postgres 11’s built in sha256 function, but it would mean getting the ID back
with a returning clause, and that doesn’t work with on conflict do
nothing).
The worker doesn’t need to worry whether another worker has already written
this template to the table - if it has, it will have the same hash and (unless
there’s an incredibly unlikely hash collision) the same template, and the
insert will silently do nothing.
Writing to the emails table is simple:
insert into emails (body_template_id, placeholders, email_address)
values
(
E'\\xC0930168570D829F...'::bytea, -- the hash of the template
'{"Fatima", "www.example.com/unsubscribe/1f7a345e"}',
'fatima@example.com'
)
When the worker that needs to send these emails comes along, it doesn’t need to do any additional work - that can all be handed off to the database with a query like:
select format(template, variadic placeholders), email_address
from emails
join body_templates on emails.body_template_id = body_templates.id
Assuming that the template uses a format that’s compatible with postgres’s format function.
Conclusions - what should we do with our database?
We still haven’t done enough of an investigation into our database’s performance to be sure that the issues we’re seeing would be resolved by reducing the amount of email body we’re writing (although that seems a likely suspect to me).
If further investigation shows that excessive email body writing is a cause of some of our issues, we should think hard about whether this approach is the easiest thing for future developers to understand - if there’s a way we can do this without resorting to clever tricks we should definitely do that instead.
Whatever we decide, I’ve enjoyed having a think about this, and now that I’ve written it up hopefully my mind can move onto more interesting things (like the bottle of tequila we’ve got in the kitchen).